Je parlais l’autre jour de l’utilisation de Cormas dans Docker et j’avais évoqué la possibilité d’utiliser cette plateforme multi-agent à l’intérieur d’openMole pour pouvoir bénéficier des possibilités de la taupe pour paralléliser le calcul et explorer des modèles.
J’avais profité de Romain pendant le coding-camp 2018 pour qu’on propose une première version de plug-in cormas pour openMole. En plus d’ouvrir des portent au calcul pour Cormas, l’idée était de permettre à l’équipe de développer de se concentrer sur le développement de la plateforme plutôt que sur le redéveloppement des méthodes de calcules.
Etape 1 : un container OpenMole
Pour tester Cormas dans openMole le plus simple est d’utiliser docker. En effet l’équipe openMole propose un joli petit container qui rox les poneys ! Vous pouvez le lancer comme ça :
## telecharger la derniere image docker pull openmole/openmole:8.0-SNAPSHOT ## cree un conteneur avec les droit décriture sur le dossier monte docker run -u root -v /root/openMole_workSpace:/var/openmole openmole/openmole:8.0-SNAPSHOT chown -R openmole:openmole /var/openmole/ ## lancer le contener en mode detache docker run --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -p 8080:8443 -v /root/openMole_workSpace:/var/openmole/ openmole/openmole:8.0-SNAPSHOT
Etape 2 : le plug-in cormas pour OpenMole
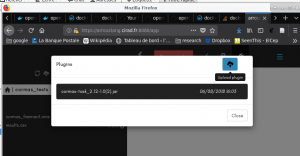
Voilà la primitive cormas n’est pas directement intégrée à OpenMole, il faudra donc télécharger le plug-in, et l’importer en utilisant le bouton idoine (la prise électrique) dans la barre d’outils en haut.
Etape 3 : Le script OpenMole
Une fois que le plug-in est installé, il ne reste plus qu’à exécuter un script. Pour se simplifier la vie, on utilisera pour l’exemple un modèle chargé par défaut dans cormas : le modèle des pompiers. Pour ceux qui n’ont pas une petite idée ce que c’est, on a un automate cellulaire dont les cellules passe de arbre à brulé et des agents pompier qui vont essayer d’éteindre l’incendie.
Vous pouvez maintenant crée un script.oms qui sera executable par OpenMole.
// OpenMole Variable definition.
// Those variables will be populated in openMole
// and send in JSON to Pharo/Cormas
val seed = Val[Int]
val numberOfFires = Val[Int]
val numberOfFiremen = Val[Int]
val percentageOfTrees = Val[Double]
val dimensionMin = Val[Int]
val dimensionMax = Val[Int]
val nbTrees = Val[Int]
// The CORMASTask take in parameters the class and method able to
// launch our simulation. In OUr case using the Cormas-Model-FireAutomata
// we run a methods build for OpenMole. You can take a look.
// set() allow you to pass some other thing to your task. You can pass :
// * your model as a file.st
// * inputs from OpenMole Variable
// * outputs as an array
// * defined parameters how doesn't change between simulation.
val model = CORMASTask("CMFireAutomataModel simuOpenMole") set (
//resources += workDirectory / "Cormas-Model-FireAutomata.st",
inputs += seed,
cormasInputs += numberOfFires,
cormasInputs += numberOfFiremen,
cormasInputs += percentageOfTrees,
cormasInputs += dimensionMin,
cormasInputs += dimensionMax,
cormasOutputs += nbTrees,
outputs += (seed, numberOfFires, numberOfFiremen, percentageOfTrees, dimensionMin, dimensionMax),
numberOfFires := 3,
numberOfFiremen := 10,
percentageOfTrees := 0.65,
dimensionMin := 60,
dimensionMax := 80
)
// With the DirectSampling() method you define an easy wait to generate
// a sampling for numberOfFires between 1 to 10.
DirectSampling(
evaluation = model hook CSVHook(workDirectory / "results.csv"),
DirectSampling(
evaluation = model hook CSVHook(workDirectory / "results.csv"),
sampling = (numberOfFires in (1 to 10)) x
(seed in (UniformDistribution[Int]() take 10))
)
Dans ce script la partie propre à Cormas est bien sûr la CORMASTask(). Elle devra contenir l’ensemble des instructions qui seront passées au docker de cormas. Dans l’exemple ici, nous fixons tous les paramètres par défaut. C’est dans la méthode DirectSampling() que l’on va faire varier le nombre de feux a l’initialisation et qu’on définira le nombre de réplications du modèle.
Etape 4 : passer à l’échelle
À l’étape précédente, on utilise un seul thread de l’ordinateur. Pour passer à l’échelle rien de plus simple, il faut simplement modifier la fin du script :
val env = LocalEnvironment(2) // With the DirectSampling() method you define an easy wait to generate // a sampling for numberOfFires between 1 to 10. DirectSampling( evaluation = model on env hook CSVHook(workDirectory / "results.csv"), sampling = (numberOfFires in (1 to 10)) x (seed in (UniformDistribution[Int]() take 10)) )
On définit une variable env qu’on va ensuite appelée dans évaluation. Notre variable env fera alors tourner les modèles en parallèle sur … 2 thread. Si vous avez accès à plus en local, n’hésitez pas à pousser. Enfin si vous avez la chance d’avoir accès à un cluster il ne vous reste plus qu’a explorer les différents environnements pris en charge par OpenMole.
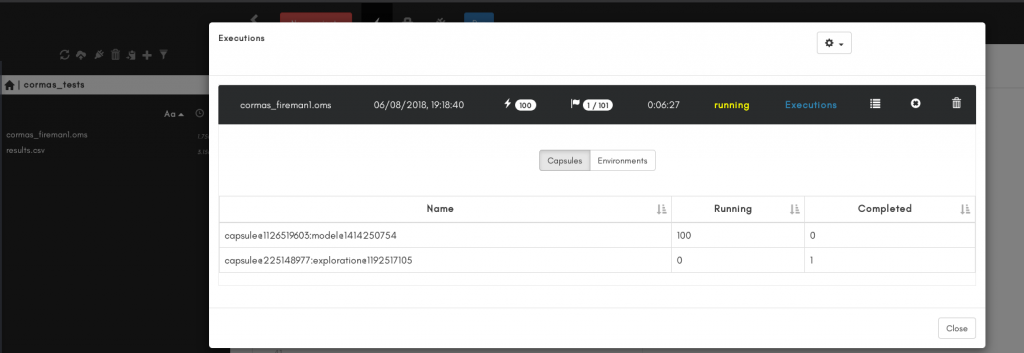
Voilà par exemple sur un cluster SGE, 100 jobs lancés que l’on peut monitor dans l’interface openMole
et que l’on peut voir sur le cluster avec qstat