Dans un précédent post, je faisais mes premiers pas avec Docker. Arrive rapidement la situation où, vous avez deux conteneurs. L’un avec une base de données spatiale en développement et l’autre avec LA base de données en production.
Bon, et il peut arriver qu’on veuille sauvegarder les données et/ou restaurer ces données. Typiquement. Vous avez peuplé votre base de nouvelles tables, vues, fonctions… et c’est le moment de passer tout ça en production… Voilà une piste !
Sauvegarder la base de données avec pg_dump ou pg_dumpall
La Nasa propose depuis 1999 des images MODIS (Moderate-Resolution Imaging Spectroradiometer) à différentes résolutions spatiales et temporelles. Elles sont produites par deux satellites en orbite, Terra (1999) et Aqua (2002), qui embarquent des capteurs pour le programme Earth Observing system.
Les instruments permettent d’enregistrer 36 bandes spectrales avec une fréquence de passage de 1 à 2 jours. La résolution des images diffère selon les bandes enregistrées et varie entre 0.25 et 1 km. Nous parlions il y a quelques jours du site reverb|echo de la Nasa, il se trouve qu’un certain nombre d’images sont disponibles sur le site.
Quelles données ?
Mais pour ça il faut savoir ce qu’on cherche, et la nomenclature des produits n’est pas vraiment transparente [1]. À titre d’exemple :
MOD9Q1 – Surface Reflectance 8-Day L3 Global 250m
MOD13Q1 – Vegetation Indices 16-Day L3 Global 250m
MOD11A2 – Land Surface Temperature/Emissivity 8-Day L3 Global 1km
Une fois qu’on en sait un peu plus sur le type de produit que l’on veut utiliser, il va falloir le télécharger et le traiter. Dans un post précédent, j’expliquais comment configurer sa machine pour utiliser wget. Si vous optez pour cette solution, il vous faudra utiliser le MRT pour reprojeter et assembler vos images. L’interface est assez intuitive et on peut faire du traitement de masse.
Mais je suis tombé aussi ce matin sur les logs de release d’un package R que je me suis empressé de tester : MODIStsp. Si vous avez déjà regardé MRT, MODISStsp n’est qu’un moyen de rester dans R pour télécharger les images. On pourra aussi regarder du côté du package MODIS qui lui n’intègre pas d’interface graphique.
Bon mais on parlait de NDVI dans le titre !
Traiter les images NDVI : MOD13Q1
En cherchant comment traiter les images MODIS, je suis tombé sur des ressources intéressantes. Notamment une page qui vous prend par la main pour traiter les données MODIS (MOD13Q1) dans R[2]. Je vous propose donc de faire un petit point pas à pas !
J’ai téléchargé et projeté les données grâce au package MODISStsp. J’ai donc un dossier qui contient les fichiers hrf, mais aussi un autre qui contient les fichiers tiff produits par le package.
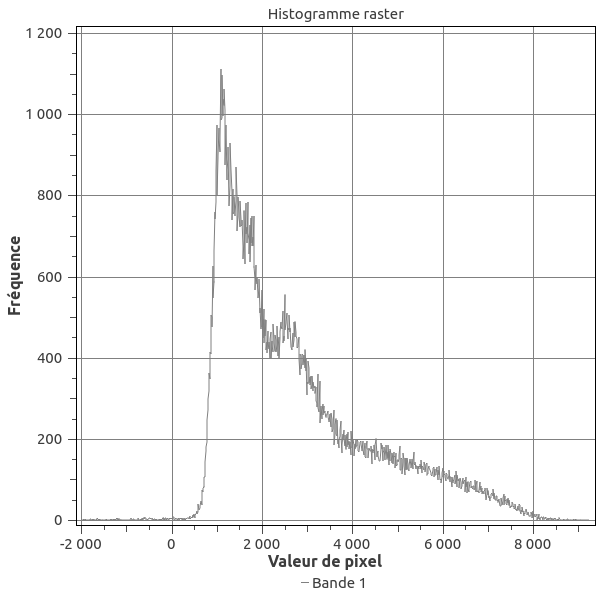
Or quand on ouvre les données (dans Qgis), les gammes de valeurs ne correspondent pas à celles attendues pour du NDVI! On devrait avoir des valeurs entre -1 et 1 !
Freq. pour la tuille 16 – 17/01/2016
Il va falloir retravailler le raster pour obtenir les bonnes valeurs . Heureusement « the office of outer space affaire » nous donne la marche à suivre dans R[3]. Je vous propose donc ici un script commenté et customisé pour l’occasion.
library(raster)
library(sp)
library(doParallel)
library(rgdal)
library(magrittr)
rm(list = ls()) ##clear env.
#create stack from tif NDVI files
path.v = "~/Documents/futurSahel/MOD13Q1_TS/VI_16Days_250m_v6/NDVI/"
l.files = list.files(path.v, pattern = ".tif")
my.stack = stack(paste0(path.v,l.files)) ##create raster stack of files in a directory
# load borders
border = shapefile("~/Documents/futurSahel/Senegal_gadm.org/SEN_adm0.shp") #ToDo: insert link to the shapefile with the country borders
## We use doParallel and magrittr packages to pipe different actions (crop and mask)
registerDoParallel(6) #we will use 6 parrallel thread
result = foreach(i = 1:dim(my.stack)[3],.packages='raster',.inorder=T) %dopar% {
my.stack[[i]] %>%
crop(border) %>%
mask(border)
}
endCluster()
ndvi.stack = stack(result)
ndvi.stack = ndvi.stack*0.0001 #rescaling of MODIS data
ndvi.stack[ndvi.stack ==-0.3]=NA #Fill value(-0,3) in NA
ndvi.stack[ndvi.stack<(-0.2)]=NA # as valid range is -0.2 -1 , all values smaller than -0,2 are masked out
names(ndvi.stack) = seq.POSIXt(from = ISOdate(2016,1,17), by = "16 day", length.out = 23) # atribut name as date for each layer
my_palette = colorRampPalette(c("red", "yellow", "lightgreen")) #Create a color palette for our values
## Plot X maps in the same layout
spplot(ndvi.stack, layout=c(4, 6),
col.regions = my_palette(16))
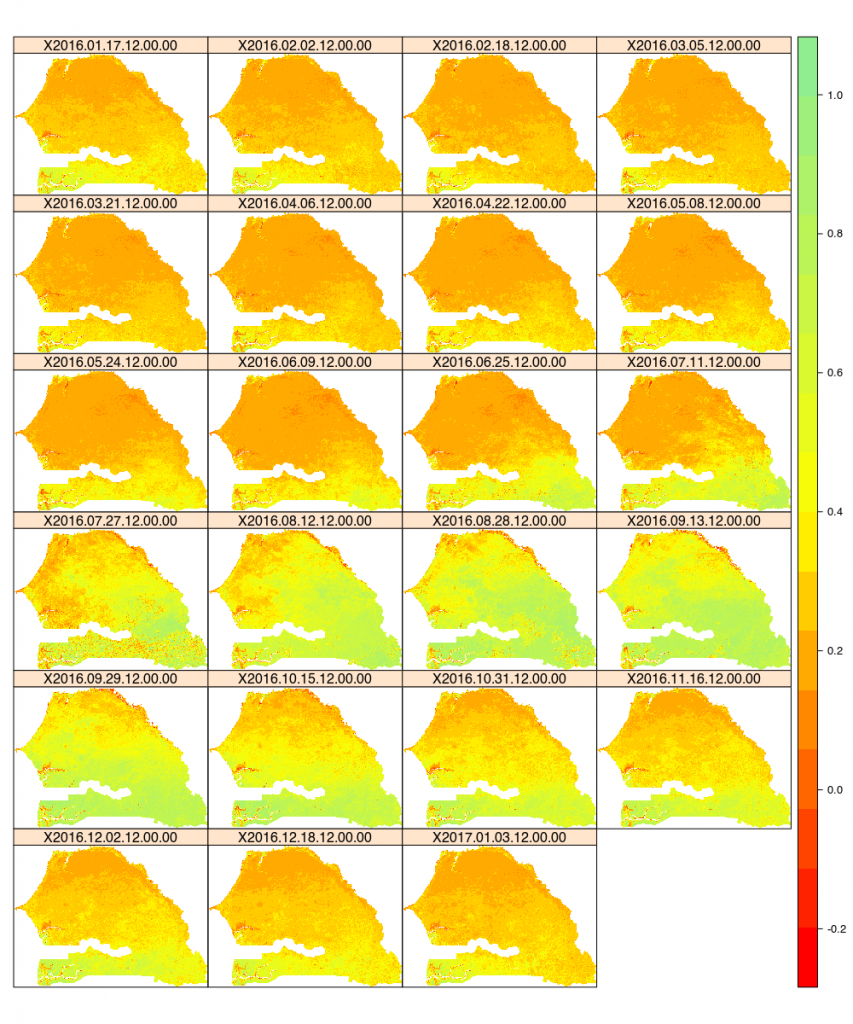
Ce qui nous donne pour les 23 pas de temps étudiés l’image suivante. On voit bien reverdir la partie supérieure de la carte entre juillet et octobre en 2016.
Indice NDVI à partir des données MODIS MOD13Q1 sur le Sénégal pour 2016
Pour avoir un ordre d’idée, traiter 23 images et produire le graphe, en parallélisant une partie, me prend 11 min .
Voilà plusieurs mois que je n’avais pas pris le temps de faire un post sur mon blog !
On trouve toujours beaucoup d’excuses, des papiers sur le feu, un déménagement, un nouveau post-doctorat… Alors pour recommencer doucement, une petite note sur un service de la NASA que j’ai découvert aujourd’hui : Reverb | echo[1]
Un peu de contexte à cette découverte, mon nouveau post-doc m’a amené à sortir de ma zone de confort, on s’éloigne de la viticulture et de l’eau (encore que), pour travailler sur la zone sahélienne du Sénégal. Je cherchais des indicateurs de désertification… Et je suis tombé sur un blog génial de Martin Brandt[2] (chercheur au Department of Geosciences and Natural Resource Management à l’université de Copenhagen (Denmark)). En plus de pointer sur des papiers scientifiques, il y a aussi quelques posts sur des outils de télédétection (GRASS-GIS) et des liens vers des pourvoyeurs de données. C’est là que j’ai découvert LE truc.
Reverb est un silo de données environnementales propulsées par la NASA qui contient des choses incroyables et un puissant moteur de recherche. Je vous engage donc à regarder cette petite vidéo d’explication[3] (en anglais).
Je ne reviendrai pas sur la manière de trouver ses données, la vidéo est là, par contre une chose géniale qui pourrait inspirer d’autres sites : une fois que j’ai fait mon petit marché, le service me propose de télécharger un fichier TXT contenant les URLs des ressources demandées. L’idée est génial. Il y a quelques semaines, j’avais du faire une centaine de copier-coller depuis le site opendata.gouv.fr pour pouvoir automatiser un traitement sur le RGP de 2012[4] (j’en parlerai peut-être dans quelques mois quand l’article sera publié).
Donc une grande satisfaction, je disais, pour cette bonne pratique… je voulais donc me lancer dans un script bash et du wget… mais les ennuis arrivent …
wget http://e4ftl01.cr.usgs.gov//MODV6_Cmp_B/MOLT/MOD09Q1.006/2016.09.05/MOD09Q1.A2016249.h16v07.006.2016258071050.hdf
Connexion à urs.earthdata.nasa.gov (urs.earthdata.nasa.gov)|198.118.243.33|:443… connecté.
requête HTTP transmise, en attente de la réponse… 401 Unauthorized
Échec d’authentification par identifiant et mot de passe.
URL transformed to HTTPS due to an HSTS policy
Mince un login ! Nooon ! Pourtant Martin Brandt ne semble pas avoir ce problème. La solution est en deux étapes. Dans un premier temps, il faudra se créer un compte « earthdata » en cliquant sur login en haut à gauche. Ensuite, et la solution est sur le wiki [5], il faudra faire un petit fichier de config « curl ».
Avec @fabio_zottele, nous nous sommes replongés ce weekend sur un travail un peu vieux. Celui-ci remonte à 5 ans, et consiste à proposer un algorithme basé sur des librairies/logiciels libres afin de détecter les terrasses viticoles. Ce travail avait initialement été développé sur R gdal et grass 6.3. pour une petite zone de la val di Cembra.
Notre objectif est aujourd’hui de systématiser l’algorithme et de vérifier que l’évolution des technologies et des algorithmes sur lesquels nous nous étions basés produit toujours le résultat attendu.
Installation de GRASS7
La première chose à faire est de compiler GRASS-GIS en version 7, car les dépôts ne sont pas encore à jour sur Fedora. Vous pouvez trouver toute la documentation sur le wiki de grass.
On pourra commencer par télécharger le weekly snapshot du projet , et installer les dépendances qui vont bien :
Et nous voilà avec une belle installation de grass7. Je vous encourage à faire un tour du propriétaire parce qu’un travail formidable a été fait ! Bravo à l’équipe de dev!
Comment se passe la communication avec R ?
Et bien figurez-vous qu’il y a le package qui va bien 😀 : rgrass7 qui s’installe comme d’habitude dans R avec :
install.packages(« rgrass7 », dependences = TRUE)
Mais l’utilisation diffère un peu de son grand frère. En effet, on peut désormais spécifier l’emplacement de votre GRASS7 fraichement compilé. On procèdera donc de la manière suivante :
remove(list=ls())
## Configuration Parametrs:
gisBaseLocation = "/opt/grass" #where the GRASS executables are
library(rgrass7) #load lib in R
initGRASS(gisBase=gisBaseLocation, override=TRUE) #Run GRASS in & Cancel previous running GRASS instance in R
L’exécution se fait ensuite avec une seule et même commande R à laquelle on passera en paramètre la commande GRASS
Un très petit post de blog pour garder sous le coude deux ou trois petites choses qui peuvent servir quand on veut préparer rapidement des données SIG pour netlogo…
J’ai eu besoin là tout de suite de découper une couche vectorielle, mais je n’avais pas à ma disposition de couche pour faire le clip… Donc j’ai cherché un moyen d’utiliser la bbox (non ce n’est pas la box de chez Bouygues Telecom mais boundary box : le rectangle qui contient toutes les entités vectorielles)
Eh bien j’ai trouvé sur un post de Tim Sutton (Linfiniti.com) des petites astuces pour me simplifier la vie :
Définir la bbox
Tim propose un petit script bash qui fait des merveilles et que je me permets de reprendre ici :
On peut ensuite bien tranquillement profiter de la commande que je proposais dans le précédent post sur le sujet, où en lieu et place du shapeFile nous pouvons passer directement l’emprise!
Attention le fonctionnement de gdalwrap est un peut différent de l’option clipsrc … il faudra réorganiser les coordonnées. On effectuera la découpe comme ça :
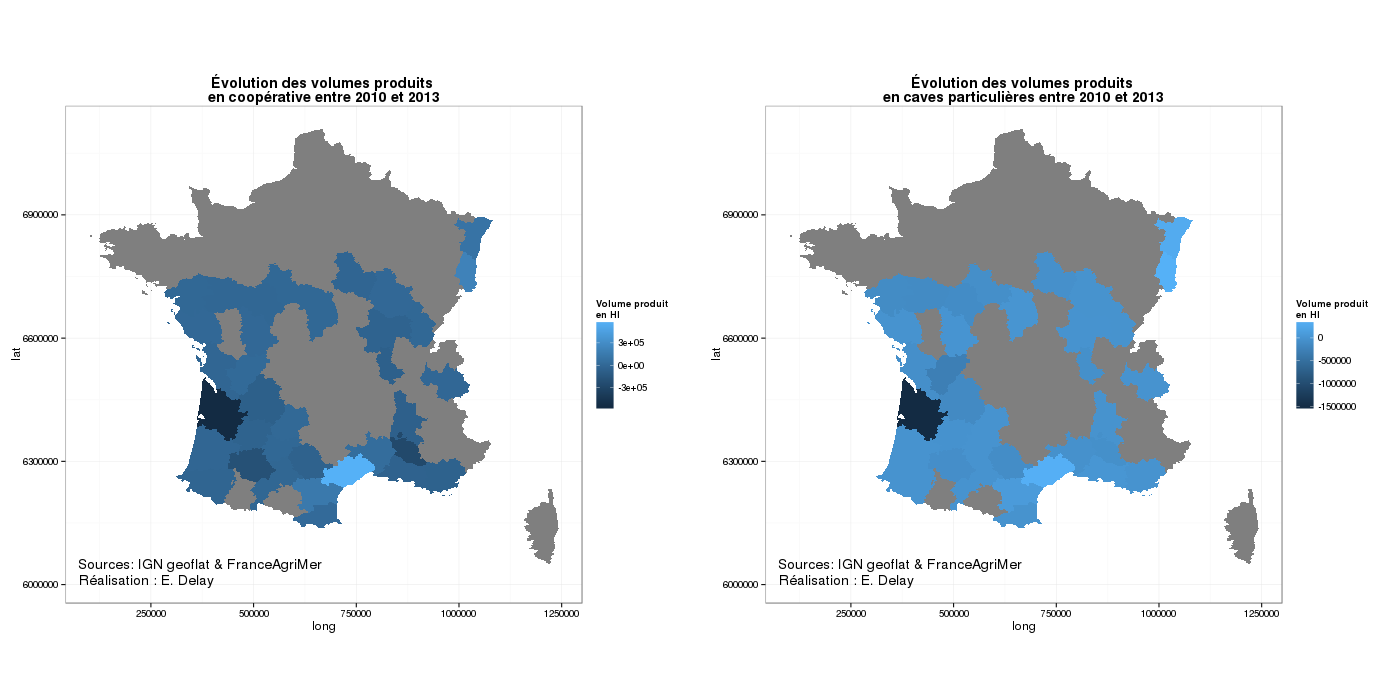
les volumes vinifiés par les coopératives ou les caves particulières par commune
etc.
Comme je suis en plein travail sur le poids du système coopératif sur le cru Banyuls (dans les PO), j’ai regardé les données auxquelles je pouvais accéder sur le site de l’observatoire. J’ai été enchanté de découvrir dans la rubrique vinification des données diachroniques (entre 2007 et 2013) sur les quantités totales livrées aux coopératives ou vignifiées par des caves particulières, mais aussi type de vin (AOP rouge/rosé, AOP blanc, IGP rouge/rosé, IGP blanc, et sans IGP).
Une véritable mine d’or donc ! Hier soir, prenant mon courage à bras le corps, je me suis lancé dans la récupération des données, et ce sur plusieurs années (2010 et 2013). Un travail long et fastidieux (qui aurait pu être simplifié si les possibilités de téléchargement des données avait été optimisées, mais bon quand on veut, on peut !).
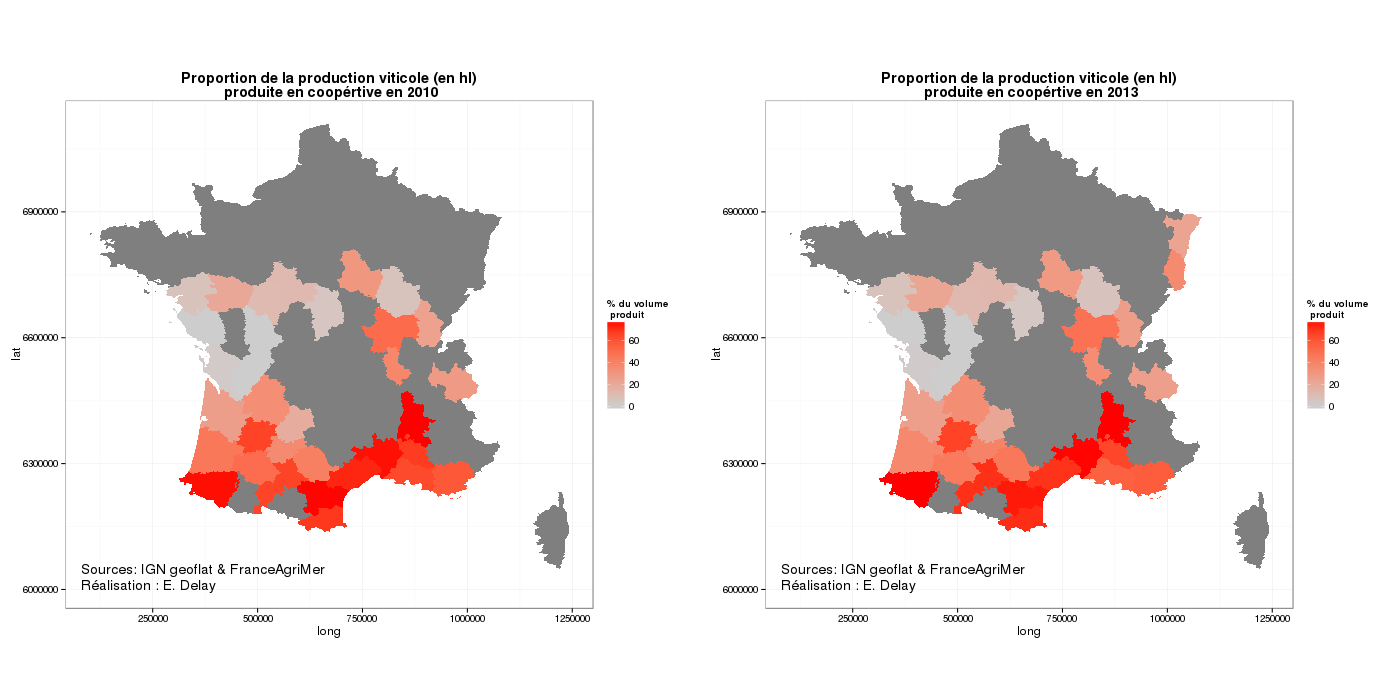
Voilà donc les deux premières sorties graphiques :
Sur ces deux premières cartes on peut essayer de jouer au jeu des 7 erreurs :
Les bouches ont légèrement reculé
Le Haut-Rhin et le Bas-Rhin sont entrés en course avec des volumes non négligeables
Les volumes ont un peu augmenté dans les Pyrénées orientales
Si ensuite on s’intéresse à l’évolution des volumes apportés aux coopératives et vinifiés par des caves particulières entre 2010 et 2013, on produit alors les cartes suivantes :
La première chose qu’on peut noter est la différence d’ordre de grandeur entre les volumes gagnés (ou perdus) par les caves coopératives et ceux générés par les caves particulières. On peut observer deux petites choses. Les volumes produits aussi bien par les coopératives que par les caves particulières entre 2010 et 2013 sont en réduction en Gironde et en augmentation pour le département de l’Hérault. La progression semble également positive pour les départements du Bas Rhin et du Haut Rhin.
Vous pouvez retrouver le matériel et la méthode sur github
J’essaie de reconstruire petit à petit sur les ruines de l’ancien blog, réutiliser une belle pierre pour en faire un appui de fenêtre, et essayer de conserver une trace des travaux qui ne servent à rien, mais qui me tiennent à cœur malgré tout.
Je me suis donc lancé ce soir sur les traces d’un vieux billet perdu à tout jamais (même sur archive.org). Un billet qui avait commencé sur un air de défi pour moi suite à une belle news de portail SIG.
En janvier 2014 donc Francois-Nicolas ROBINNE publiait un petit article pour signaler l’existence d’une base de données construite et mise à disposition par l’université d’Adélaïde, en Australie.
Cette base de données reprend, par pays les surfaces plantées pour 1200 cépages (connus et moins connus). Or, quand on parle d’informations et de pays, un géographe a envie de faire des cartes. En prenant au mot la remarque François-Nicolas je vous propose donc quelques cartes des cépages mondiaux et moins mondiaux…
Morceaux choisis de géographie viticole
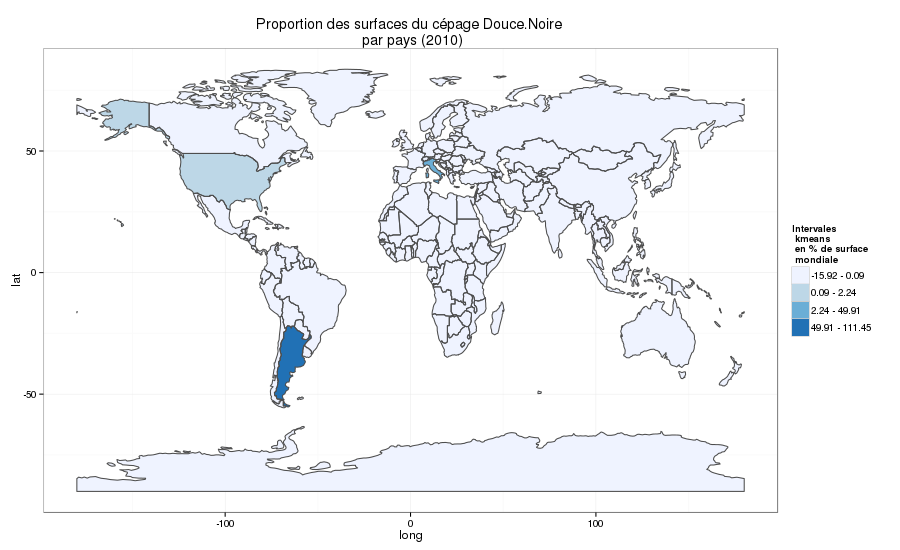
La Douce Noire (le Corbeau)
Répartition de la Douce Noire dans le monde en 2010
La douce noire (le nom que lui préfèrent les Savoyards) aussi appelée corbeau (dans les registres officiels), a été réautorisée à la culture dans toute la France en 2009 . C’est un raisin de cuve noir, qui était jadis largement cultivé dans le massif du mont Blanc (connu en Italie sous le nom Dolcetto negro). Comme on le voit sur la carte, il est largement cultivé en Argentine, mais commence à être réintroduit en France grâce aux efforts du Centre d’Ampélographie Alpine (et particulièrement R. Raffin et M. Grisard). Il est particulièrement intéressant en ces temps de changement climatique, car il produit un vin peu alcooleux. En Savoie, il était généralement mélangé dans les parcelles avec du Persan et de la Mondeuse qui sont deux cépages de seconde époque (ce qui permet une vendange simultanée).
Selon l’inventaire des cépages de 1957 que j’avais étudié et cartographié pendant un stage au Centre d’Ampélographie Alpine il en restait 499ha en Savoie.
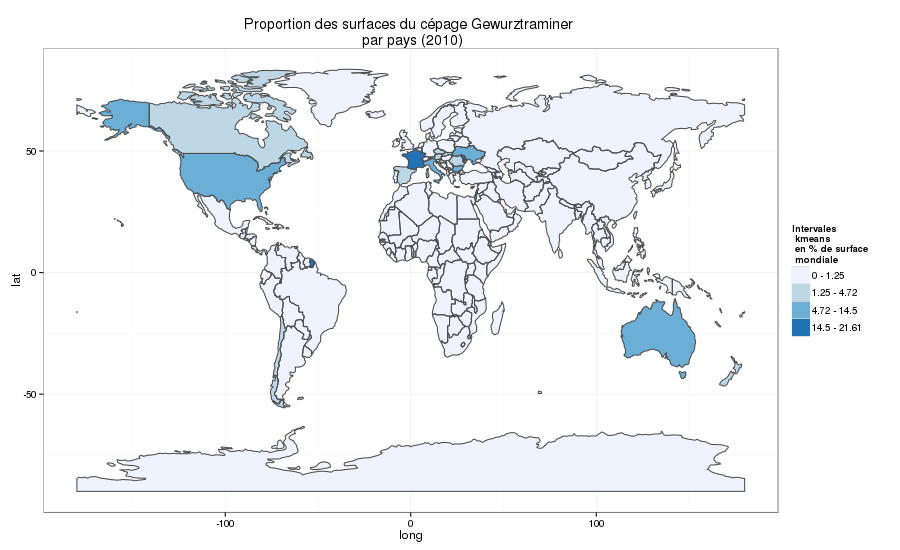
Le Gewurztraminer (ou traminer aromatico)
répartition du Gewurztraminer à travers le monde
Le 2nd cépage sur lequel je voudrais m’arrêter est le Gewurztraminer ou Traminer aromatico pour les Italiens. Car si ce cépage est bien connu en France en particulier à cause de l’AOC alsacienne, c’est à nos voisins italiens que je dois l’une des plus belles réussites. Je travaille dans la vraie vie avec la fondazion E.Mach dans le Trentino en Italie. Et il se trouve qu’on cultive très largement le Traminer aromatico dans cette région. Pour les besoins de ma thèse j’ai donc fait quelques séjours prolongés. Le contexte du Val Di Cembra ou de l’Alto Adige sont particulièrement propices à ce cépage rose.
Si d’autres cépages vous intéressent, les scripts R et les (82) cartes sont sur github. Vous pouvez jouer avec les scripts et si, comme L. Jegou, vous voulez éviter cet horrible mercator, vous pouvez forker et jouer avec la fonction coord_map() de ggplot2 (Attention les surprises! la simplification de polygones a été fait avec les pieds)
C’est un sujet que j’avais déjà traité dans un post antérieur, mais comme le blog de l’époque a disparu, il a fallu que je me replonge dans les bas-fonds de postgresql, postgis et pgRouting. Heureusement que les articles de Anita Graser (alias underdarck) sont encore en ligne, eux, mais ils ont nécessité quelques ajustements avec pgRouting 2!
Si vous en êtes là c’est que vous cherchez un moyen de faire des calculs d’isochrones et que, petit à petit, la solution pgRouting (même si elle peut sembler disproportionnée) s’impose à vous.
A ce stade, je partirais du principe que vous avez un serveur postgreSQL/postGIS fonctionnel. Vous trouverez plusieurs ressources sur Internet. Pour ma part, j’ai réalisé ce petit tuto sur Fedora 20 (un bon tuto pour l’installation postgresql postgis su le blog de Marcus Neteler et pgRouting est dans les packages de la distribution).
Ensuite, il faut importer un shapefile dans postgreSQL. Vous pouvez utiliser un client graphique comme shp2pgsql-gui ou deux petites lignes de commande (des infos ici )
#transformer en requête SQL un shapefile
shp2pgsql -I -t 2D -s 2154 reseau_total_AOC.shp acces_banyuls access_banyuls > acces_banyuls.sql
#envoyer les données dans la base
psql -f acces_banyuls.sql -d geodb
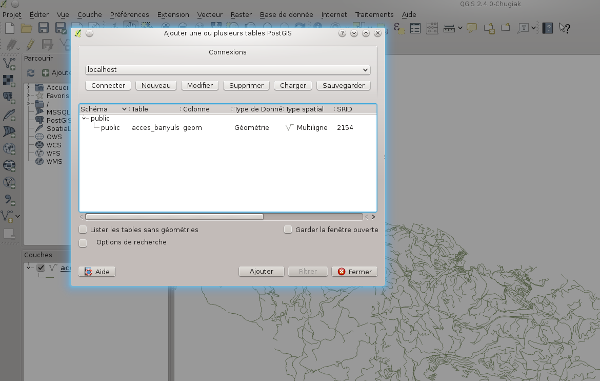
Vous pouvez dès à present vous connecter à la base avec QGIS et avoir accès aux données
connection à postgreSQL avec QGIS 2.4
Pour pouvoir créer un graph connecté, il faut identifier pour chaque ligne ou polyligne le début et la fin. C’est ce que nous allons faire avec :
--evaluer le type de la colonne geom
select * from geometry_columns;
--pour évaluer la dimension des coordonnées de vos géométries
select distinct st_coordDim(geom) from acces_banyuls;
--convertir la colonne en deux dimensions si les données sont en 2D si vous n'avez pas utilisé l'option -t 2D de shp2pgsql
alter table acces_banyuls alter column geom type geometry(Multilinestring, 2154) using st_force2D(geom);
On va ensuite devoir transformer des multiLine-string en line-string dans postGIS parce que dans sa version 2 pgRouting ne travaille plus qu’avec ça .
--d'utilisation de st_dump pour transformer multiLine-string en line-string
CREATE TABLE simple_ways AS SELECT *, (ST_Dump(geom)).geom AS simple_geom FROM acces_banyuls WHERE geom IS NOT NULL;
--au passage on suprime la colonne multiline string
ALTER TABLE simple_ways DROP COLUMN geom;
On va ensuite créer une colonne temps de trajet à partir d’une colonne existante dans la base de données qui contient, pour chaque tronçon, la vitesse limite :
--mise à jour des temps de trajet
ALTER TABLE simple_ways ADD COLUMN length_m INTEGER;
UPDATE simple_ways SET length_m = st_length(st_transform(simple_geom,2154));
ALTER TABLE simple_ways ADD COLUMN traveltime_min DOUBLE PRECISION;
UPDATE simple_ways set traveltime_min = length_m / (vtss_pt / 60 * 1000) --pour avoir la vitesse en metre
On peut ensuite essayer les fonctions de pgRouting proposer par Anita Graser
-- ajouter des col "source" et "target" à la table
ALTER TABLE acces_banyuls ADD COLUMN "source" integer;
ALTER TABLE acces_banyuls ADD COLUMN "target" integer;
--Creation de colonne startPoint et endpoint (syntaxe à changer ne pas oublier st_)
CREATE OR REPLACE VIEW road_ext AS
SELECT *, st_startpoint(simple_geom), st_endpoint(simple_geom)
FROM simple_ways;
--Une table qui contient tout les noeuds
CREATE TABLE node AS
SELECT row_number() OVER (ORDER BY foo.p)::integer AS id,
foo.p AS the_geom
FROM (
SELECT DISTINCT road_ext.st_startpoint AS p FROM road_ext
UNION
SELECT DISTINCT road_ext.st_endpoint AS p FROM road_ext
) foo
GROUP BY foo.p;
--creation du réseau -> 128330 ms
CREATE TABLE network AS
SELECT a.*, b.id as start_id, c.id as end_id
FROM road_ext AS a
JOIN node AS b ON a.st_startpoint = b.the_geom
JOIN node AS c ON a.st_endpoint = c.the_geom;
Pour la dernière commande il faut faire attention, en effet à chaque fois que vous regénérez une table node, les id de ces derniers peuvent changer. Donc quand vous allez devoir spécifier l’ID du noeud source (6791 dans la requête suivante), faites attention de bien le mettre à jour.
--Creation de la table qui contient les temps de trajet
--besoin d'une colonne avec travelTime pour faire le calcul
-- temps de calcul 123190 ms
create table cost_road as
select
id,
the_geom,
(select sum(cost) from (
SELECT * FROM pgr_dijkstra('
SELECT gid AS id,
start_id::int4 AS source,
end_id::int4 AS target,
traveltime_min::float8 AS cost
FROM network',
6791,
id,
false,
false)) as foo ) as cost
from node;
Vous pouvez ensuite charger ces points dans Qgis et lancer une interpolation avec l’extension interpolation, par exemple, qui va vous en proposer deux types :
TIN (Triangulated Irregular Netwaork)
IDW (Inverse Distance Weighted)
Voilà le résultat d’une interpolation IDW (avec une discrétisation moche je vous l’accorde 🙂 mais on a qu’à dire que c’est pas l’objet ici).
Ou, si vous voulez une interpolation plus propre, vous pouvez aussi passer sous R.
L’intégration de données SIG dans netlogo n’est pas une trivial. Je vous propose donc ici un petit pense pas bête pour passer de données SIG dans une projection hétérogène à l’intégration dans netlogo. J’en avais déjà fait un il y a quelques années, mais comme je repart de zero… autant approfondir!
Prè-requis : gdal, qgis, netlogo
découpe et reprojection de données raster
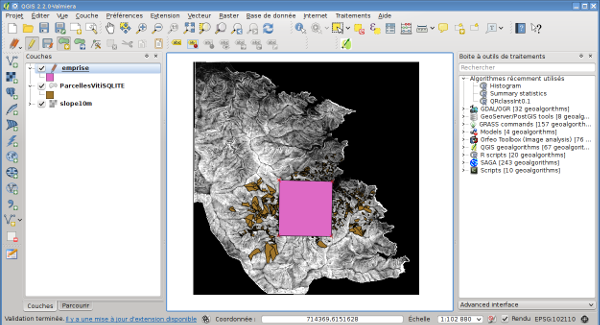
Dans mon cas, je veux travailler sur un espace carrée, je commence donc par définir l’emprise de la zone de travail avec un polygone dans Qgis.
Si vous vous intéressez a ces questions, vous savez sans doute que l’extension GIS de netlogo ne supporte pas un très grand nombre de système de projection. Il va donc falloir passer ici du lambert 93 (epsg:2154) au WGS84 (epsg:4326) ce qui nécessite un ré-échantillonnage du raster.
Nous allons utiliser gdal en ligne de commande pour effectuer la reprojection et la découpe en même temps.
Si vous ré-ouvrez a nouveau Qgis vous pouvez vérifier que tout s’est bien passé (découpe et epsg = 4326)!
Mon 2nd problème maintenant est que netlogo mange de l’asc … il faut donc traduire mon tif en asc ! Cela peut encore une fois se faire garce à gdal! (attention depuis la version 1.9 de gdal il faut force la création de grid type ESRI… par défaut gdal produit un fichier de type surfer, cela est possible avec l’option -co FORCE_CELLSIZE=TRUE)
Si on veux effectuer la même chose avec des données vectorielle on va utiliser le couteau suisse ogr2ogr qui vient avec les librairies gdal. De la même manière donc nous sommes capable de découper et reprojeter des données vecteur
Attention tout fois, vérifiez que les champs qui vous intéressent ne sont pas NULL
Import dans netlogo de données vecteur
A ce stade nous n’avons (plus) qu’ à passer dans netlogo.
Vous devrez en premier lieu charger l’extention GIS dans netlogo et definir des global à utiliser pour charger les données SIG.
Extensions [GIS]
breed [vinegrowers vinegrower]
globals[
parcelles ;; needed for GIS vector import
]
patches-own [ ;;atributes for patches
cat ;;for load data from GIS dataSet
]
Nous pouvons à partir de là créer une procédure qui va charger des données GIS.
to setupGIS
;chargement des données en RAM
;;definir le systeme de projection
set parcelles gis:load-dataset "data_carto/ParcellesVitiSQLITE/small_parcellesWGS84.shp"
gis:set-world-envelope gis:envelope-of parcelles
;efface la vu dans l'interface
clear-drawing
;definition de la couleur pour les polygones
gis:set-drawing-color blue
;definition des la couche (charger dans les gloables) a dessiner dans l'interface
gis:draw parcelles 1
;ajuste le cadre de l'environement de netlogo avec la couche shp
gis:set-world-envelope (gis:envelope-of parcelles)
;affectuer des valeurs du vectordataset (champs N_CVI) aux patches dans l'atribut cat
gis:apply-coverage parcelles "N_CVI" cat
end
Si vous appelez la fonction setupGIS dans l’interface les données sont charger dans le viewer
Extensions [GIS]
breed [vinegrowers vinegrower]
globals[
parcelles ;; needed for GIS vector import
]
patches-own [ ;;atributes for patches
cat ;;for load data from GIS dataSet
]
Nous pouvons à partir de là créer une procédure qui va charger des données GIS.
to setupGIS
;chargement des données en RAM
;;definir le systeme de projection
set parcelles gis:load-dataset "data_carto/ParcellesVitiSQLITE/small_parcellesWGS84.shp"
gis:set-world-envelope gis:envelope-of parcelles
;efface la vu dans l'interface
clear-drawing
;definition de la couleur pour les polygones
gis:set-drawing-color blue
;definition des la couche (charger dans les gloables) a dessiner dans l'interface
gis:draw parcelles 1
;ajuste le cadre de l'environement de netlogo avec la couche shp
gis:set-world-envelope (gis:envelope-of parcelles)
;affectuer des valeurs du vectordataset (champs N_CVI) aux patches dans l'atribut cat
gis:apply-coverage parcelles "N_CVI" cat
end
Import dans netlogo de données raster
Extensions [GIS]
breed [vinegrowers vinegrower]
globals[
parcelles ;; needed for GIS vector import
slope
]
patches-own [ ;;atributes for patches
cat ;;for load data from GIS dataSet
slope_here
]
Nous pouvons à partir de là créer une procédure qui va charger des données GIS.
to setupGIS
;chargement des données en RAM
;;pour charger les pentes
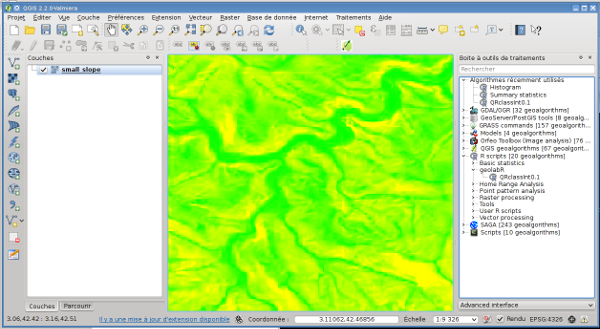
set slope gis:load-dataset "data_carto/DTMBanyulsEPSG2154/small_slope.asc"
;;poue simplement dessiner le raster
gis:paint slope white
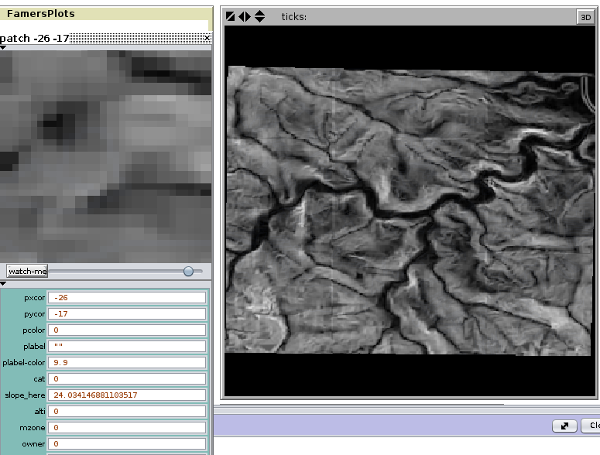
;;pour attribuer les valeur du raster aux patches
ask patches[
set slope_here gis:raster-sample slope patch pxcor pycor
]
end
Ce qui nous permet d’obtenir l’effet attendu (ouf)!
A noté enfin que les valeurs vont se superposer dans l’ordre dans lequel vous les appelez dans la procédure. Ce qui veuux dire que si vous avez charger des données vecteur n premier et que vous ajouter la pente comme ici. Les polygones que nous visualisions précédement seront cacher par la pente.
Tout à commencer après les élections municipales, nous discutions avec @joelgombin de cartographie avec R et de résultats d’élection… dans ma naïveté je pensais qu’il existait un site regroupant tous les résultats des élections, un peu à la manière de cartelec. J’avais dans l’idée de proposer aux L1 de Géographie à Limoges dont je m’occupe de travailler sur la discrétisation univariée avec R sur ces données brûlantes d’actualité. Travail d’autant plus intéressant (à mon sens) que France3 Limousin proposait sur son site des cartes de ces résultats sans en préciser les modalités de création .
Retrouver et commenter la discrétisation des cartes de France3, un exercice intéressant si tant est que je puisse avoir accès aux données (électorales et spatiales). Pour les données spatiales, le site cartelec propose des fichiers spatiaux que je me suis empressé de découper à l’échelle de Limoges, et le site de la mairie propose un PDF des résultats par bureau de vote (parfait ça colle avec le shapefile).
Donc me voilà parti à scraper le PDF pour intégrer les données au shapefile de cartelec ! Et c’est en suite que les problèmes ont commencé !
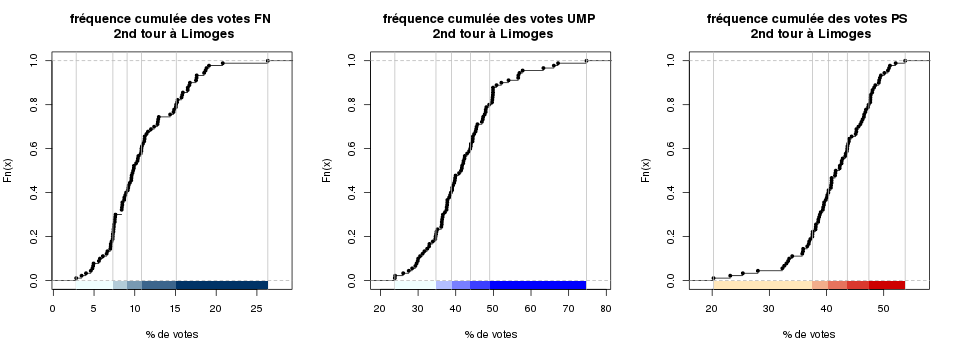
Une fois la jointure réalisée, et grâce au package classInt on découvre les premiers résultats !
2nd tour des élections municipales à Limoges. Les lignes verticales représentent les bornes de classes pour une classification par les quantiles
On pourra par exemple utiliser la syntaxe suivante :
classifQ=classIntervals(data$pct_GERARD,n=5,style="quantile")
pal1=c("#F0FFFF", "#003366") #définition des extrémités de la palette de couleurs
plot(classifQ,pal=pal1,
main="fréquence cumulée des votes FN \n 2nd tour à Limoges",
xlab="% de votes") #plot des effectifs cumulés
Effectuer une classification, qu’elle soit supervisée ou automatique, n’est jamais anodin. De cette étape dépend une très grande partie de l’information qui va être perçue par le lecteur.
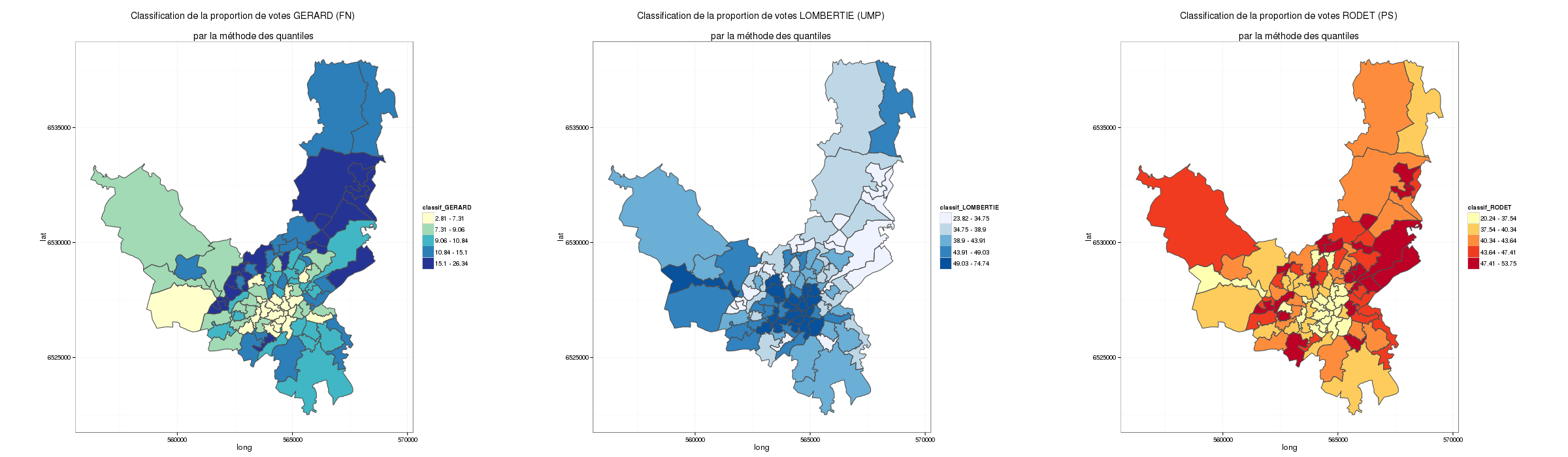
Ainsi en utilisant une classification par quantiles, on obtient ce type de carte.
Cartographie des résultats du 2nd tour des municipales à Limoges par bureau de vote.
Ici on à utiliser ggplot2 avec la syntaxe suivante
##préparation de la legende
# Create labels from break values
brks=round(classifQ$brks,digits=2) ##definition des breaks
intLabels=matrix(1:(length(brks)-1))
for(j in 1:length(intLabels )){intLabels [j] = paste(as.character(brks[j]),"-",as.character(brks[j+1]))}
label_GERAD=intLabels
fn=ggplot()+
geom_polygon(data=bureau.df, aes(x=long,y=lat,group=group,fill=classif_GERARD))+
geom_path(data=bureau.df, aes(x=long,y=lat,group=group),color="grey30")+
scale_fill_brewer(type="seq", palette="YlGnBu",labels = label_GERAD)+
labs(title ="Classification de la proportion de votes GERARD (FN) \n
par la méthode des quantiles")+
theme_bw()+
coord_equal()
fn
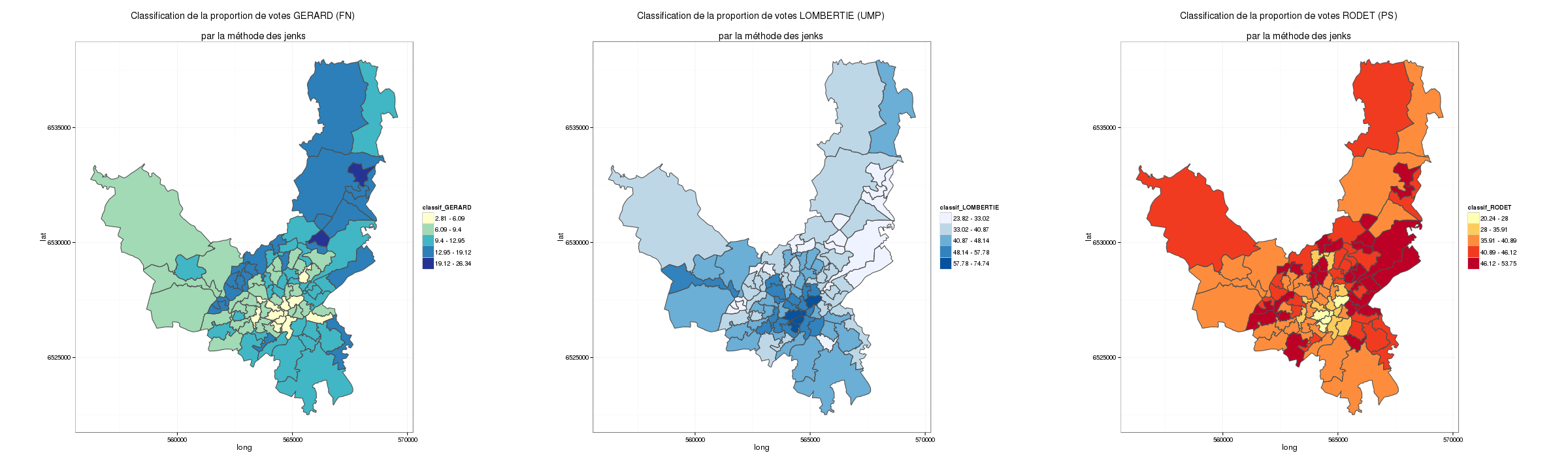
On pourrait s’amuser à comparer le rendu en utilisant une classification par la méthode de Jenks (méthode des sauts naturels).
Cartographie des résultats du 2nd tour des municipales à Limoges par bureau de vote. Classification par la méthode de Jenks
On constate que la carte change d’allure. Si l’on s’intéresse à la carte de gauche représentant le vote FN à Limoges, certains bureaux de vote (sur la partie droite) qui étaient considérés comme appartenant à la classe la plus haute par une classification par les quantiles se retrouvent dans une classe plus intermédiaire avec une analyse par jenks…
La classification par Jenks me semble ici plus intéressante (je vous laisse vous reporter aux courbes de fréquences cumulées) car des « seuils » sont visibles sur les courbes.
Mais revenons au ce qui nous occupait. La cartographie proposée par France3, et des comparaisons. Le problème maintenant, vient de la résolution spatiale. En effet, elle n’est pas basée sur des résultats par bureau de vote, ce qui ne va pas nous aider à retrouver la méthode de classification !
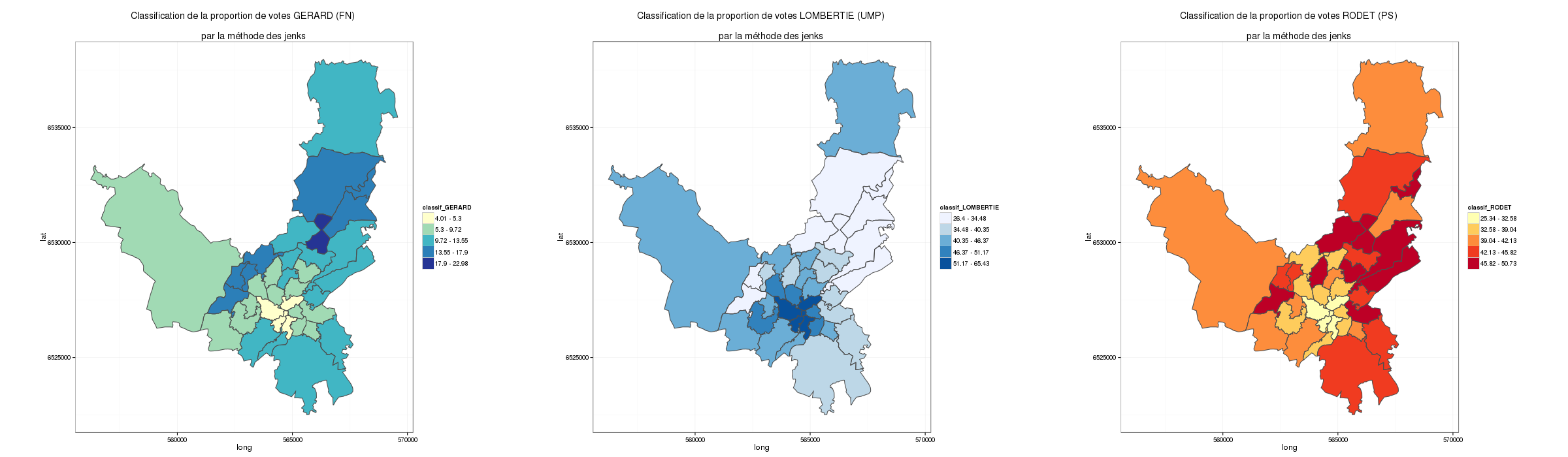
C’est là qu’est intervenu F.Cerbelaud en effectuant un regroupement des résultats par bureau de vote en se basant visuellement sur la carte de France3.
Voici les nouvelles cartes produites quand on applique aux données une classification par la méthode de jenks (c’est la méthode de classification automatique qui donne les résultats les plus proches de la carte de France3)
Cartographie du 2nd tour des élections municipales à Limoges. Bureaux de vote regroupés selon la carte de France3. Classification Jenks
On voit très bien le type de changement de représentation qu’opèrent ces regroupement. Il est donc nécessaire, pour pouvoir comprendre une carte, de connaître la signification des regroupements d’entités spatiales (ici pour France3 des regroupements de bureau de vote) ainsi que le type de classification qui a été utilisé pour traiter les données. Quand on touche à des sujets aussi sensibles, une mise en contexte de l’objet cartographique ne me paraît pas ici superflu, car on voit très bien que chaque étape dans le traitement des données influence l’objet cartographique.