Depuis la sortie en 2022 de chatGPT, les solutions basées sur des IA sont partout. La question n’est plus, il me semble : « comment vivre sans ? », ou encore « est-ce qu’il est souhaitable de mettre de l’IA partout ? » une question qui ne nous a jamais été posée collectivement.
Xavier De La Porte résume très bien mon état d’esprit dans l’intro de son podcast (le code a changer : Série « Humains-machines : nos langues entremêlées » Épisode 1/2 : Une histoire d’interruption ) : « je crois que je n’en peux déjà plus des discussions autour de ce que nous racontent les IA. Je n’en peux déjà plus d’entendre des gens s’extasier de tout ce que savent les IA, ou, a contrario, se plaindre de leurs hallucinations. Je n’en peux plus des gens qui me détaillent ce qu’ils font avec GPT, Claude, Perplexity ou Le Chat. »
L’IA est là, elle étend son emprise, est-ce que je peux limiter ma zone de contact en gardant le « contrôle » sur ce que je donne à la machine ? Parce que la tentation est de plus en plus forte de donner aux promptes des papiers scientifiques, des rapports, etc. pour lui demander des résumés… Bien sûr qu’il faut les avoir lus pour espérer échapper aux hallucinations, mais le temps que je pourrais gagner à lui faire faire cet élagage est sans commune mesure. Ce qui me pose évidemment la question de gagner du temps pour faire quoi ? Et bien, pour le moment c’est la théorie de la reine rouge. Comme tout le monde utilise chatGPT, pour aller plus vite, je suis toujours à la traine.
Bien sûr, céder à ce chantage, c’est faire un pas de plus dans le rêve des machines de Günther Anders ! Nous devenons toujours plus consommateurs :
« si nous sommes considérés comme de meilleurs travailleurs, notre consommation sera d’autant plus satisfaisante et nous pourrons accomplir plus rapidement le devoir qui nous incombe d’œuvrer comme liquidateur ; les produits apparaissent d’autant plus réussis qu’ils sont capables de se laisser rapidement user par nous. » (G. Anders, 2022, p.85)

Donc comment garder le contrôle ? En gardant l’IA dans sa boite — c’est à dire dans ma machine. Rien ne fuite car tout reste là en local sur mon ordinateur.
Techniquement comment j’ai fait ?
Installer Ollama c’est facile
Ollama c’est facile a installer sur Linux :
curl -fsSL https://ollama.com/install.sh | sh
Cet utilitaire fonctionne un peu comme docker. On fournit un nom de modèle et il se charge de le télécharger et de le faire fonctionner. Une fois l’utilitaire installé, il faudra donc télécharger des LLM. Il y en a une flopé disponible sur le site. À titre d’exemple, voilà celui que j’essaie en ce moment.
ollama run gpt-ossNormalement en sortie de commande (après le téléchargement de plusieurs Go de modèle), vous tomberez dans un prompt dans le terminal. Pour en sortir ctrl + d.
Installer open-WebUI c’est moins évident
Avant tout, j’ai perdu pas mal de temps à essayer de comprendre pourquoi les modèles que j’avais téléchargés avec Ollama n’étaient pas visibles dans l’interface de open-WebUI. Il se trouve qu’il y a encore des incompatibilités entre open-WebUI et Firefox. J’ai fini par trouver les infos là!
Donc, pour installer le service web, la solution proposée est basée sur docker. Chez moi, c’est passé avec cette commande :
sudo docker run -d --network=host -v open-webui:/app/openWebUI -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:mainUne fois que le docker est lancé, il met quelques minutes à s’instancier correctement. On peut accéder au service en local : http://localhost:8080/
RetEx à chaud 🪖
Après quelques essais, c’est chouette, mais ce n’est pas encore le futur! Déjà ça va pousser les « vieilles » machines dans la tombe et accentuer la fracture numérique. Ici une requête sur le modèle GPT-OSS occupe pas mal ma machine.
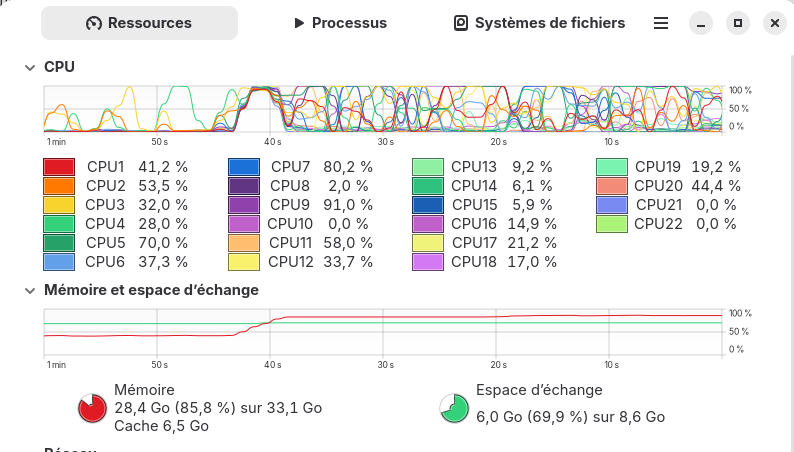
Je cherchais quelque chose qui me permette de faire de la synthèse de fichier. Le point positif c’est que c’est possible d’envoyer des fichiers au LLM dans l’interface d’open WebIU (qui intègre RAF), mais les formats ne sont pas tous supportés (PDF, odt, et autre format libre oui), mais les formats propriétaire comme docx semblent non pris en charge… Ensuite le niveau de réponse n’est pas foufou, et très dépendant du modèle qu’on charge. D’un point de vue contextuel, peut être que cela dépend des réglages de l’interface, mais la priorité n’est pas donnée au fichier que vous fournissez. Il arrive que se glissent des informations de fichier analysé précédemment.
Quelques références :
- Une video de Korben : https://www.youtube.com/watch?v=XHl-guck9po
- la doc de open-webUI : https://docs.openwebui.com