Du 7 au 10 juillet 2014 s’est déroulé en Hongrie le bien connu (dans le milieu autorisé) congrès terroir. Cet évènement a regroupé, comme tous les deux ans, près de 200 chercheurs du monde entier pendant quelques jours dans la petite ville hongroise de Tokaj, pour échanger autour de cette notion (ô combien complexe) du terroir.
Les échanges que j’ai eu lors de ce congrès m’ont donné envie, une fois de retour en France, de revisiter les données produites par mon petit script qui moissonne, depuis plusieurs mois, les tweets parlant de terroir.
L’information d’un découpage mondial ?
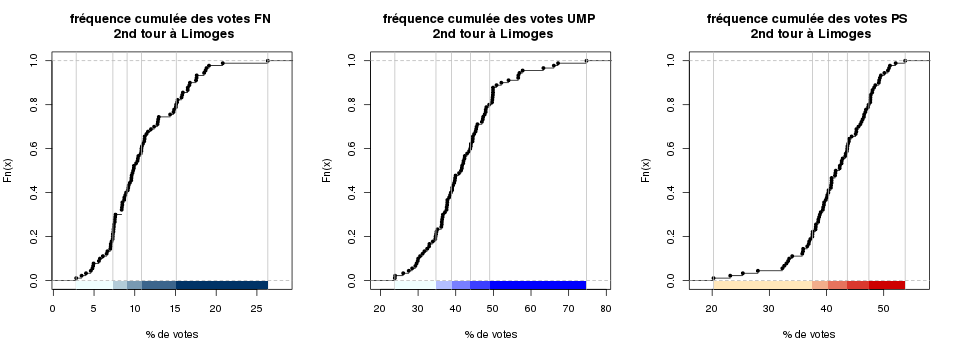
Je ne reviendrai pas sur la procédure que j’ai déjà expliquée dans un article de geotribu. J’ai effectué une classification univariée des résultats par pays pour essayer de me faire une idée de l’internationalisation du terme.
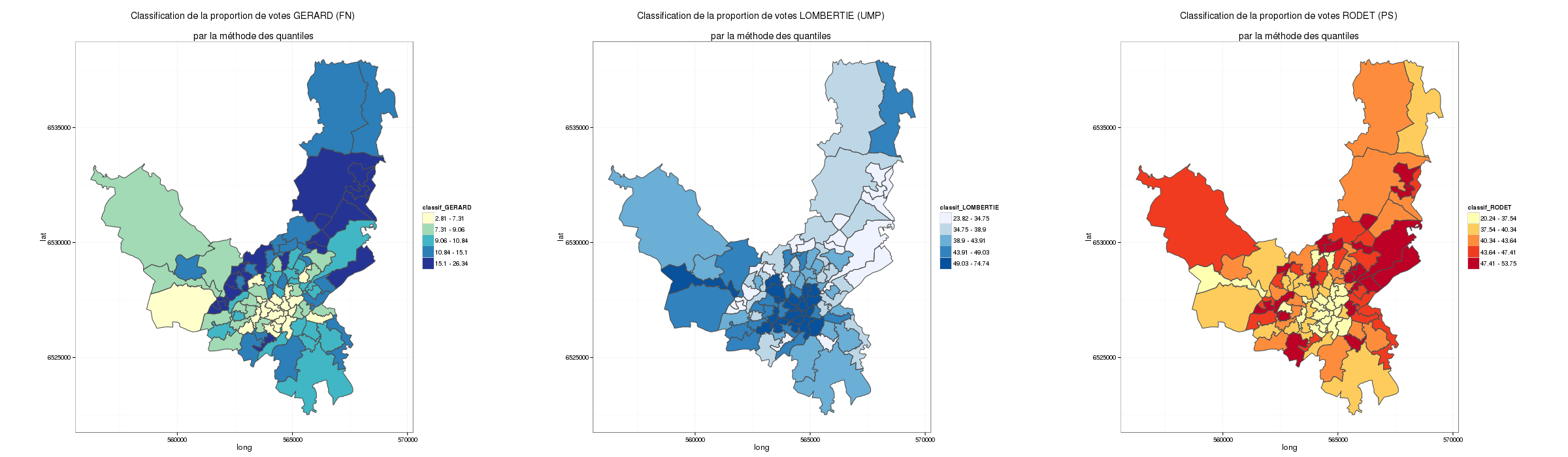
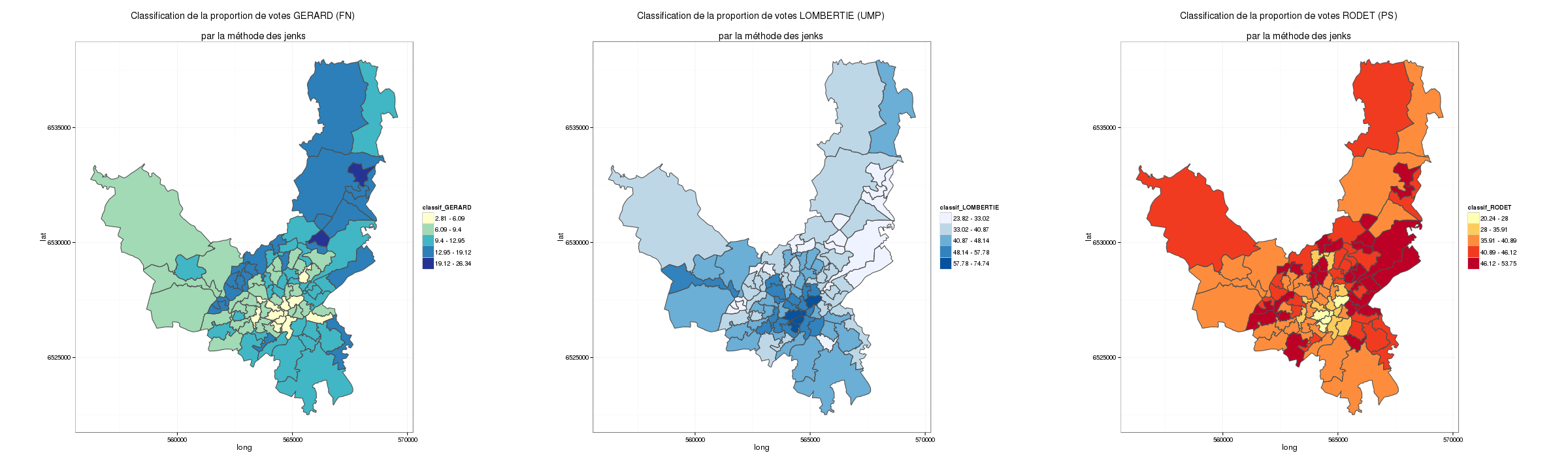
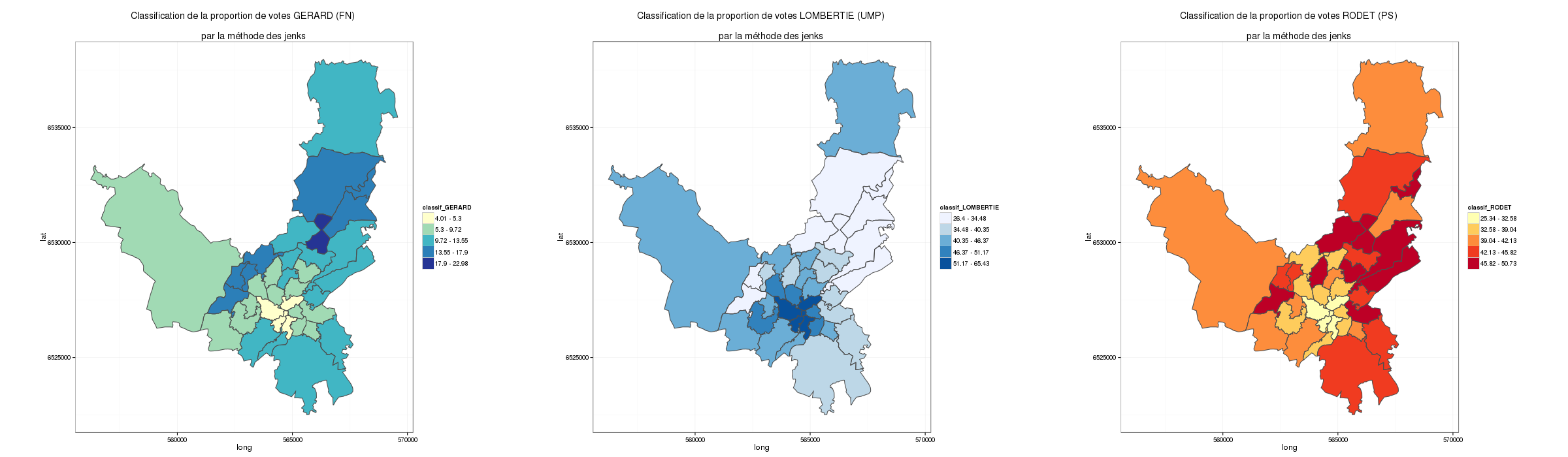
 Avec une classification automatique de jenks sur 5 classes, voilà les résultats. On constate qu’une très grande majorité des pays ne parle pas de « terroir »… Et au final parmi ceux qui en parlent, on peut constater de grands écarts entre les pays.
Avec une classification automatique de jenks sur 5 classes, voilà les résultats. On constate qu’une très grande majorité des pays ne parle pas de « terroir »… Et au final parmi ceux qui en parlent, on peut constater de grands écarts entre les pays.
 Sur cette carte (dans une projection funky (mapproj: gilbert)), on observe tout de suite que la notion de terroir est plutôt un terme utilisé par les « vieux » pays producteurs, mais pas seulement. C’est sans doute une question d’adoption du langage. En effet, les États-Unis sont dans la classe qui mobilise le plus d’utilisation (entre 21 et 34 % des tweets avec le mot « terroir ») et la France est juste derrière dans la classe 16 à 21%.
Sur cette carte (dans une projection funky (mapproj: gilbert)), on observe tout de suite que la notion de terroir est plutôt un terme utilisé par les « vieux » pays producteurs, mais pas seulement. C’est sans doute une question d’adoption du langage. En effet, les États-Unis sont dans la classe qui mobilise le plus d’utilisation (entre 21 et 34 % des tweets avec le mot « terroir ») et la France est juste derrière dans la classe 16 à 21%.
Les autres pays producteurs de vin en Europe (en particulier l’Italie et l’Espagne) sont plus loin derrière et partagent la même classe que les pays d’Amérique latine (entre 1 et 5% des tweets).
Échelle géographique nationale ?
On s’interroge ensuite tout naturellement sur la pertinence de raisonner à l’échelle nationale, et ainsi donner autant de points aux USA qu’à un pays européen. Il faut donc trouver un moyen de s’abstraire des limites géographiques.
L’exercice n’est pas trop compliqué dans la mesure où la donnée que nous récoltons est sous forme de points géoréférencés. La question reste l’échelle d’agrégation pour garder du sens. 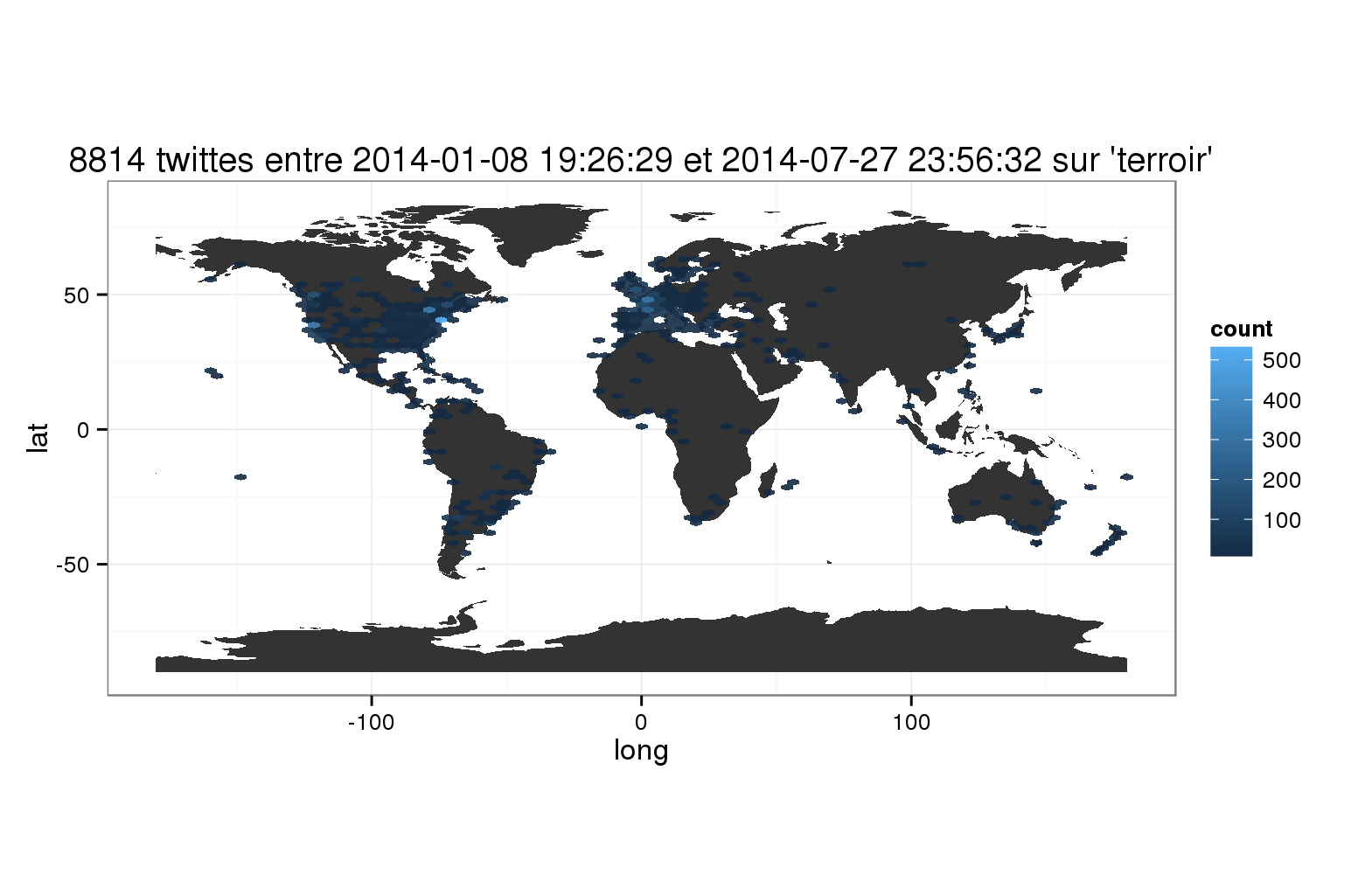
Avec cette agrégation par hexagones, on peut voir qu’il y a des inégalités spatiales dans l’utilisation du mot « terroir », et cela au sein même d’un territoire national ! Pour garder l’exemple des États-Unis, le centre du pays disparaît au profit des côtes Est et Ouest qui représentent de véritables « hotSpots » de l’utilisation du mot.
On pourrait rapprocher l’utilisation de ce mot aux zones urbaines (avec en Europe, un beau Hotspot parisien), ce qui représenterait un beau paradoxe. Peut-être parlons-nous volontiers de terroir dans un bar à vin parisien que sur les terrains viticoles de Bourgogne ou d’ailleurs :-)!
Sur ce, je vous laisse avec en prime de petites images des visites de terrain sur le vignoble de Tokaj.
Des visites de terrain
Disznoko winnery
Une winnery historique où j’ai découvert le tokaj aszu, un vin produit à partir d’une double vinification. Des raisins botrytisés d’un côté et une vinification plus traditionnelle de l’autre. Les deux sont mélangés pendant quelques jours pour que les arômes des aszu passent dans le liquide et lui donnent des notes d’abricot, tintées de menthe !
L’occasion également de déguster un tokaj eszencia… essence même des raisin aszu récoltéd par gravité !


Nobilis winnery

Un domaine familial de moins de 15ha d’où sortent des vins de tokaj fabuleux, dommage qu’ils soient compliqués à trouver en France … avis aux cavistes. Il y a quelque chose à faire ici :-). Une dégustation verticale, des comparaisons de millésimes surprenants !
PS : Pour ceux que ça intéresse, vous pouvez retrouver la présentation ( disponible sur gitHub) que j’ai faite lors de l’introduction à la session 4 du congrès. Il s’agissait de ré-explorer la pensée de Roger Dion par l’intermédiaire des SMA.